
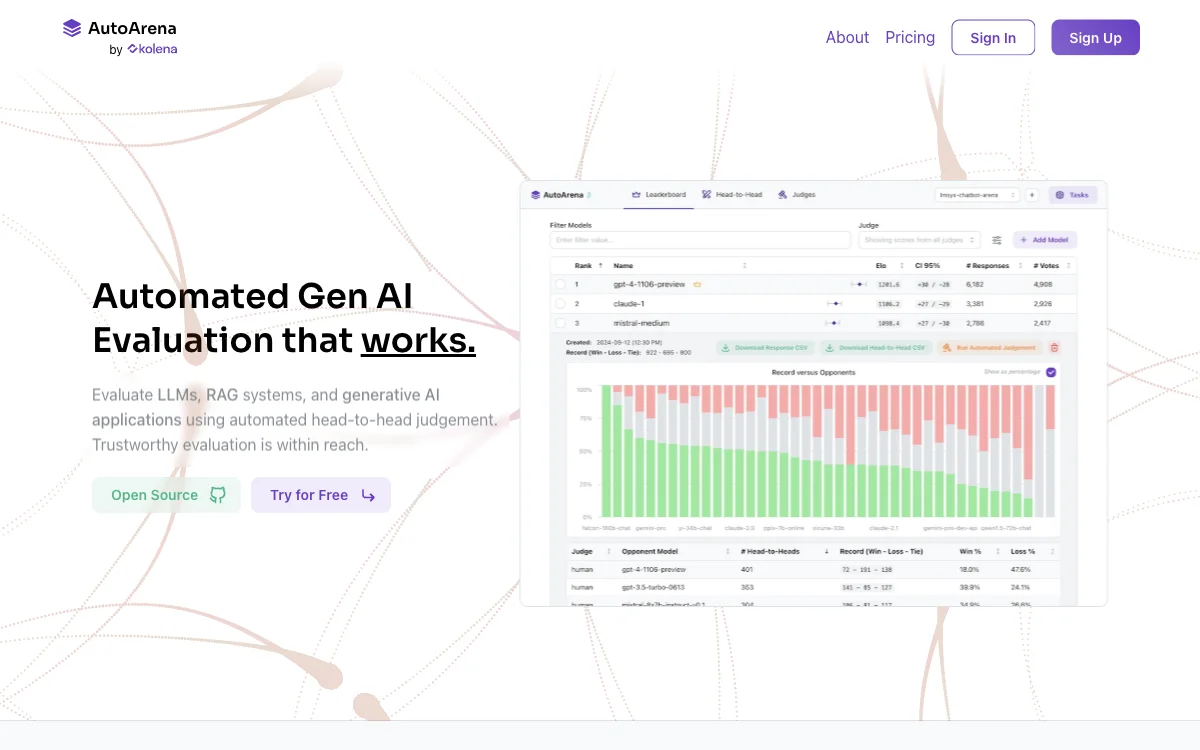
AutoArena, üretken AI uygulamalarını değerlendirmek için harika bir çözüm sunuyor. Kullanıcılar, LLM'ler, RAG sistemleri ve diğer üretken AI uygulamalarını otomatik karşılaştırmalı değerlendirme yapabilirler. Bu yaklaşım, güvenilir sonuçlar sunuyor çünkü yargı modelleri kullanarak yapılan karşılaştırmalı değerlendirme kanıtlanmış bir tekniktir. Yargı modelleri genellikle tek yanıtları değerlendirmeye kıyasla çift yönlü karşılaştırmalarda daha iyi performans gösterir.
Kullanıcılar, OpenAI, Anthropic, Cohere, Google ve Together AI gibi çeşitli sağlayıcıların yargı modellerini kullanabilir veya Ollama aracılığıyla yerel olarak çalışan açık ağırlıklı yargı modellerini tercih edebilirler. AutoArena, birçok çift yönlü oyu Elo skorları ve Güven Aralıkları hesaplayarak sıralama tabloları oluşturabilir. Birden fazla daha küçük, daha hızlı ve daha ucuz yargı modeli kullanmak, tek bir önde gelen modelden daha güvenilir bir sinyal üretebilir.
AutoArena, paralel çalışma, rastgelelik, kötü yanıtları düzeltme, yeniden deneme ve hız sınırlama gibi birçok teknik detayı hallediyor. Ayrıca farklı ailelerden yargı modelleri kullanarak değerlendirme yanlılığını azaltmaya yardımcı oluyor. Yargı modellerini daha doğru, alan - özel değerlendirmeler için ayarlamak mümkündür. Kullanıcılar, çift yönlü oylama arayüzü aracılığıyla insan tercihlerini toplayabilir ve bu tercihler, özel yargı ayarlaması için kullanılabilir.
CI ortamında, AutoArena üretken AI sistemlerini değerlendirmek için kullanılabilir. Kaynak kod depolarıyla entegre edilerek kötü prompt değişikliklerini, ön işleme veya son işleme güncellemelerini veya RAG sistemi güncellemelerini engelleyebilir. Yerel olarak, bulutta veya özel bir şirket içi dağıtımda çalışabilir. Sadece üretken AI sisteminin girişleri (kullanıcı promptları) ve çıkışları (model yanıtları) test için gereklidir. Ayrıca AutoArena Cloud'da takım işbirliği de destekleniyor.